SQLServer Batch Mode
1. SQL Server列存储
Columnstore index 列式索引也是一大特色,从SQL SERVER 2012起,支持列式索引了。我们要谈一谈列式索引的概念,用法,比较下与row-based index的区别,特别是列式索引的存储。据说列式索引采用了独特的压缩方式。这种压缩方式叫xVelocity(前称VertiPaq),专门用于 Analysis Service和Power Pivot的数据存储,现将其移到relational database storage engine中来。
- ColumnStore index data Structure: 从物理存储上来说,ColumnStore index 在page之上加了一层抽象,segment。一个segment就是一列索引的字段。如果我们新创建一个ColumnStore Index,就会有两个segment。每个segment会有一个存储的上限,每一个segment都可以包含很多数据页(data page)。一个columnstore index的所有segment,按照从上到下一一对应排序。也就是说,如果我们新建一个2列的columnstore index,第一个segment的第一个行,和第二个segment的第一个行,组成了堆表里面的第一行。
- 按照列来存储,有3个好处:一来存储的都是同质化的(homogenous)数据,压缩采用的函数比较高效;二来针对重复值比较多的列,可以采用 dictionary的方式存储,key部分存储在索引上,value部分放在dictionary 里面,省下很多空间,查询产生的IO就更小了;再一个因为每一个segment存储了单一的值,减少了一些大字段的占用空间,很多预读的数据页就极大减少了不必要字段,IO更有效率。
- Batch Mode Processing:SQL Server 有三种处理数据集的方式, 一种是 row-based, 一行一行处理,一种是 Batch mode, 一个batch包含了1000条数据,每一个列在这个batch里面被称之为vector,基于vector的处理方法,叫做batch processing。当然我们可以把row-based, batch mode合并起来应用,这是第三种方式。
2. SQL Server 2012列存储索引技术
mssql列存自SQL Server 2012引入,以应对数据分析(OLAP)和数据仓库(Data Warehouse)场景的查询。
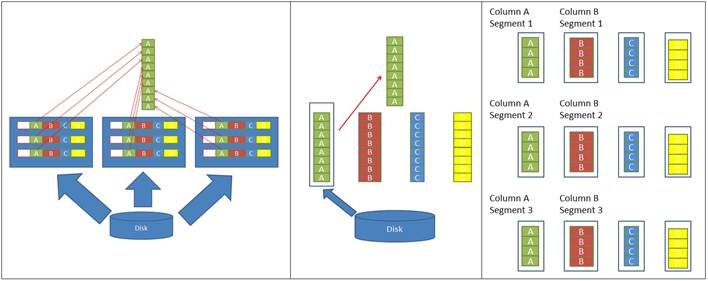
以下三张图摘自:《Inside the SQL Server 2012 Columnstore Indexes》。
- 左图: 从行存数据库中仅读取一列数据;
- 中图: 从列存数据库中读取一列数据;
- 右图: mssql列存中的Column Segment示意图。
3. 关闭Batch Mode模式
“关闭batch mode”方法比较隐蔽。可以使用 DBCC命令,DBCC命令有两种:
- 一种是微软公开的参数,有名称;
- 另一种是非公开参数,只有编号,不同版本可能不一样,微软帮助里没有说明,只能网上找。
(1)、关闭/启用所有算子Batch Mode
关闭命令(即使用row mode):
- snippet.sql
DBCC TRACEON(9453,1)
启用命令:
- snippet.sql
DBCC TRACEOFF(9453,1)
(2)、关闭/启用Sort算子Batch Mode
关闭命令(即使用row mode):
- snippet.sql
DBCC TRACEON(9347,1)
启用命令:
- snippet.sql
DBCC TRACEOFF(9347,1)
sys.column_store_segments
The following query returns information about segments of a columnstore index.
- snippet.sql
SELECT i.name, p.object_id, p.index_id, i.type_desc, COUNT(*) AS number_of_segments FROM sys.column_store_segments AS s INNER JOIN sys.partitions AS p ON s.hobt_id = p.hobt_id INNER JOIN sys.indexes AS i ON p.object_id = i.object_id WHERE i.type = 5 OR i.type = 6 GROUP BY i.name, p.object_id, p.index_id, i.type_desc; GO
打赏作者以资鼓励:
 |  |